Evaluate Wine by LSTM and Simple NN
This project is focused on solving the question: Is it possible to let the machine evaluate a wine like a sommelier?
The answer is yes! With the help of simple Neural Network and Long short-term memory(LSTM), we can make it possible.

Survival Analysis 5: Accelerated Failure-time (AFT) model
If we want to find the relationship between hazard function and other variables, we can use the Cox proportional hazards (PH) model. However, what if we want to model the survival time itself? In this case we can use Accelerated Failure-time (AFT) models.
Survival Analysis 4: Cox proportional hazards model
This post will briefly share the derivation, estimation, assumption and application of the Cox proportional hazards (PH) model. In addition, it will also mention using ANOVA to test two nested models.
Survival Analysis 3: Non-Parametric Comparison of Survival Functions
This post is to share the two common non-parametric tests of comparing the survival functions: Log-Rank Test & Generalized Wilcoxon Test, as well as their corresponding calculations in the detailed process.
Survival Analysis 2: Non-Parametric Estimation of Survival Functions
Concepts of survival function estimations and corresponding calculations both manually and in R.
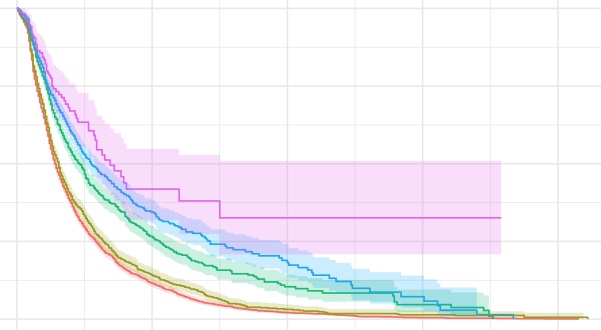
Survival Analysis 1: Basic Concepts and Three Fundamental Functions
This post covers their concepts and relationship among the three pillows of survival analysis: survivor function, density function, hazard function.

Network Influence Measures
Closeness centrality can tell us how to find important nodes in a network. The important nodes could disseminate information to many nodes or prevent epidemics, or hubs in a transportaion network, etc.

Network Connectivity
In this post I will briefly share the connectivity related concepts and functions of clustering coefficient, distance measures, and connection robustness.

Network Analysis Basics
Networks is a set of objects (nodes) with interconnections (edges). Many complex structures can be represented by networks. It is everywhere in different forms. For example, family network, Facebook communication network, subway network, food web, etc.

NLP 4: Semantic Text Similarity and Topic Modeling
Topic modeling is a useful tool for people to grasp a general picture of a long text document. Compared with LSTM or RNN, topic model is more or less for observatory purpose rather than prediction. In this post I will share the measure of similarity among words, the concept of topic modeling and its application in Python.

NLP 3: Text Classification in Python
In the previous two posts, I have shared basic concepts and useful functions of text mining and NLP. In this third post of text mining in Python, we finally proceed to the advanced part of text mining, that is, to build text classification model. In this post I will share the main tasks of text classification. Two useful classification models, their implementation in Python and methods of improving classification performance.

NLP 2: NLTK Basics in Python
In this post I will share what are the basic NLP tasks and how to deal with different tasks by using the powerful NLTK library in Python.

NLP 1:Text Mining Application in Python (RegEx)
In this exercise, we'll be working with messy medical data and using RegEx in Python to extract dates of different formats. The goal of this exercise is to correctly identify all of the different date variants encoded in this dataset and to properly standardize and sort the dates.

Causal Inference 4: Instrumental variable
Intromental variables (IV) is an alternative causal inference method that does not rely on the ignorability assumption.
Causal Inference 3: Inverse probability of treatment weighting, IPTW
In this post we will continue on discussing the estimate of causal effects. We will talk about intuition of IPTW, some key definitions like weighting, marginal structual models. And in the end we will show a data example in R.